
在数字化办公与学习场景中,快速、准确地从图像或文档中提取文字已成为刚需。然而,许多 OCR(光学字符识别)工具依赖网络连接、收费高昂,或缺乏对复杂排版和批量任务的支持。Umi-OCR 正是一款为解决这些问题而生的免费、开源、离线运行的文字识别软件。
Umi-OCR 的核心优势在于其完全离线、无需联网即可运行,所有代码与引擎均开源,保障用户隐私与数据安全。软件内置高效率的离线 OCR 引擎(支持 PaddleOCR 与 RapidOCR),并提供截图识别、批量图片处理、PDF 文档解析、二维码读取与生成等丰富功能,同时支持命令行调用与 HTTP 接口,便于集成到自动化流程中。
核心功能模块
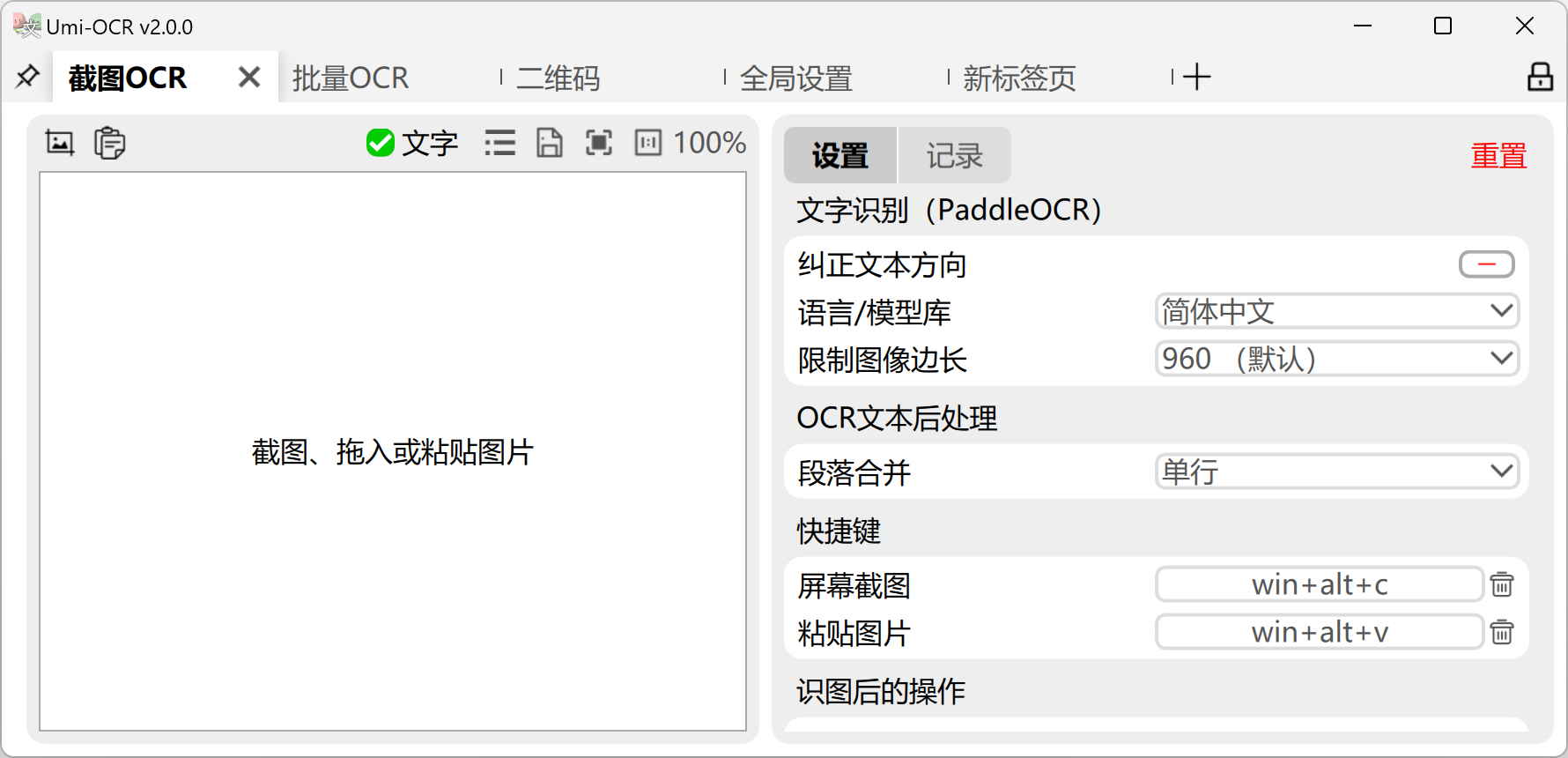
1. 截图 OCR
通过全局快捷键唤起截图工具,即时识别屏幕任意区域的文字。识别结果以文本块形式展示,支持鼠标划选复制。软件还具备“排版解析”后处理功能,可智能识别多栏、横排或竖排(从右至左)布局,并按自然段落规则输出,大幅提升可读性。此外,支持公式识别(需特定插件),满足学术与技术文档处理需求。
2. 批量 OCR
支持一次性导入数百张本地图片(JPG、PNG、WebP、BMP、TIFF 等格式),自动批量识别并导出为 TXT、JSONL、Markdown 或 CSV(Excel 兼容)格式。独创的“忽略区域”功能允许用户绘制矩形框排除水印、LOGO 等干扰元素,仅保留有效文本内容。任务完成后可设置自动关机或休眠,提升无人值守效率。
3. 文档识别

可处理 PDF、XPS、EPUB、MOBI 等多种电子书与文档格式。对于扫描版 PDF,Umi-OCR 能执行 OCR 并生成“双层可搜索 PDF”,既保留原始图像,又嵌入可选中文本。同样支持“忽略区域”设定,用于过滤页眉页脚等固定内容。
4. 二维码功能
支持读取与生成二维码及条形码,兼容 19 种协议(包括 QRCode、DataMatrix、PDF417、EAN13 等)。可识别单图中的多个码,并支持自定义纠错等级与输出参数。
灵活部署与高级扩展
多平台安装方式
- Windows:提供 .7z 压缩包、自解压包,亦可通过 Scoop 安装(支持 PaddleOCR 或 RapidOCR 引擎版本)。
- Linux:提供 Shell 脚本及运行库,适配主流发行版。
- 国内用户:推荐通过蓝奏云链接下载,免注册且不限速。
开发者友好
Umi-OCR 提供完整的命令行接口(CLI)与 HTTP API,便于与其他系统集成。项目采用模块化设计,OCR 引擎以插件形式加载,用户可自由切换或扩展。源码结构清晰,包含 Python 核心逻辑、Qt 界面资源及多语言翻译文件,支持二次开发。
个性化设置
软件支持多国语言(含简体/繁体中文、英语、日语、俄语、葡萄牙语等),界面主题(亮色/暗色)、字体大小均可自定义。首次启动时自动匹配系统语言,也可在“全局设置”中手动调整。此外,支持开机自启、托盘运行、窗口置顶等实用选项。
未来开发计划
Umi-OCR 由开发者 hiroi-sora 利用业余时间维护,依托 Weblate 平台实现多语言协作翻译,已吸引全球数十位贡献者参与本地化工作。项目在 GitHub 上持续更新,Star 数稳步增长。
未来开发计划包括:重构插件机制、增加在线 OCR 插件、独立数学公式识别模块、GPU 加速、表格识别转 Excel、历史记录系统,以及对 macOS 和 Ubuntu 等更多平台的支持。
获取方式
- GitHub Releases:https://github.com/hiroi-sora/Umi-OCR/releases/latest
- 蓝奏云(国内推荐):https://hiroi-sora.lanzoul.com/s/umi-ocr
- SourceForge:https://sourceforge.net/projects/umi-ocr
Umi-OCR 凭借其离线、免费、功能全面且高度可定制的特性,为需要高效、安全文字识别解决方案的个人用户、研究者及开发者提供了强大工具,助力构建更高效的数字工作流。

这个用了很久,超级好用
这款用过,挺不错
不错的推荐